
Microsoft is showing LLM-Augmenter, a framework designed to make ChatGPT and other language models produce less misinformation.
With OpenAI's ChatGPT, Microsoft's Bing chatbot, and soon Google's Bard, large language models have made their way into the public domain. Among other problems, language models are known to hallucinate information and report it as fact with great conviction.
For years, researchers have been developing various methods to reduce hallucinations in language models. As technology is applied to critical areas such as search, the need for a solution becomes more urgent.
With LLM Augmenter, Microsoft is now introducing a framework that can reduce the number of hallucinations at least somewhat.
Microsoft's LLM Augmenter relies on plug-and-play modules
In their work, researchers from Microsoft and Columbia University added four modules to ChatGPT: Memory, Policy, Action Executor, and Utility. These modules sit upstream of ChatGPT and add facts to user requests, which are then passed to ChatGPT in an extended prompt.
Working Memory keeps track of the internal dialog and stores all the important information of a conversation, including the human request, the facts retrieved, and the ChatGPT responses.
The Policy module selects the next action to be taken by the LLM augmenter, including retrieving knowledge from external databases such as Wikipedia, calling ChatGPT to generate a candidate response to be evaluated by the Utility module, and sending a response to the users if the response passes the Utility module's validation.
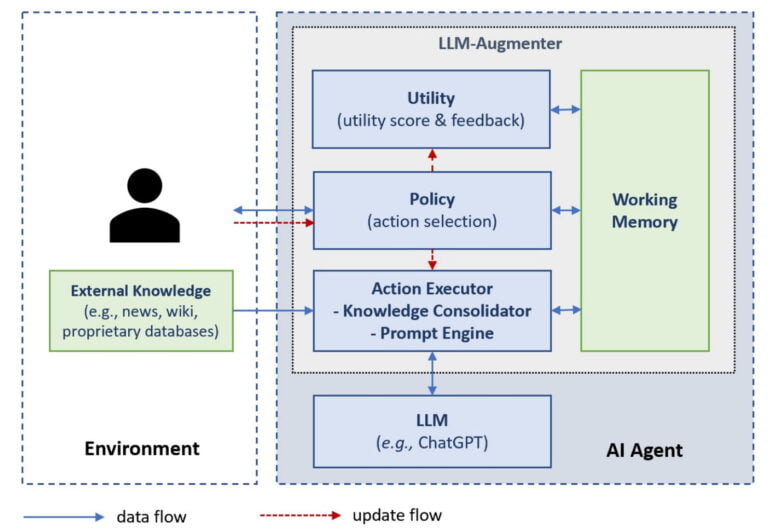
Policy module strategies can be hand-written or learned. In the paper, Microsoft relies on manually written rules such as "always call external sources" for ChatGPT due to low bandwidth at the time of testing, but uses a T5 model to show that the LLM augmenter can also learn policies.
The Action Executor is driven by the Policy module and can gather knowledge from external sources and generate new prompts from these facts and ChatGPT's candidate responses, which are in turn passed again to ChatGPT. The Utility module determines whether ChatGPT's response candidates match the desired goal of a conversation and provides feedback to the Policy module.

For example, in an information retrieval dialog, the Utility module checks whether all answers are taken from external sources. In a restaurant reservation dialog, on the other hand, the responses should be more conversational and guide the user through the reservation process without digressing. Again, Microsoft says, a mix of specialized language models and handwritten rules can be used.
LLM augmenter reduces chatbot errors, but more research is needed
In tests conducted by Microsoft, the team shows that the LLM augmenter can improve ChatGPT results: In a customer service test, people rated the generated responses as 32.3 percent more useful - a metric that measures the groundedness or hallucination of responses, according to Microsoft - and 12.9 percent more human than native ChatGPT responses.
In the Wiki QA benchmark, where the model must answer factual questions that often require information spread across multiple Wikipedia pages, LLM-Augmenter also significantly increases the number of correct statements but does not come close to models trained specifically for this task.
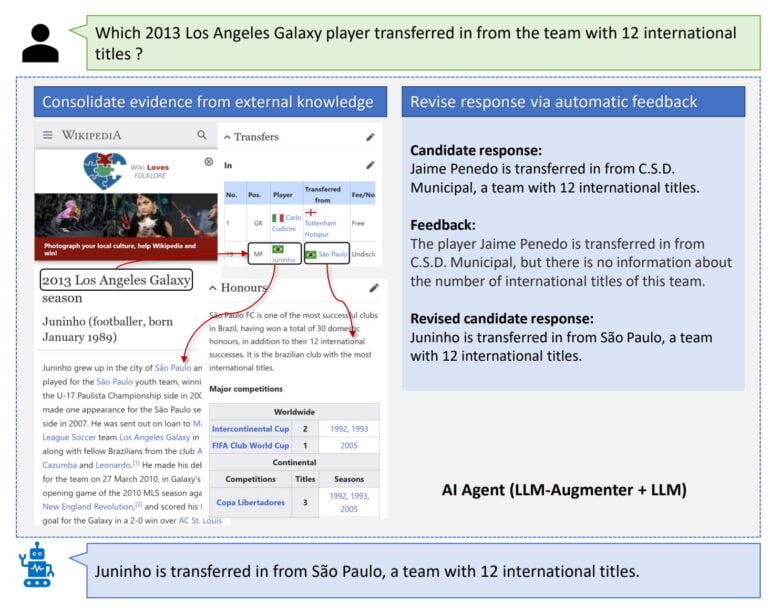
Microsoft plans to update its work with a model trained with ChatGPT and more human feedback on its own results. Human feedback and interaction will also be used to train LLM augmenters. The team suggests that further improvements are possible with refined prompt designs.
The paper does not reveal whether LLM augmenter or a similar framework is used for Bings chatbot.




