New RECAP tool exposes just how much copyrighted text LLM's can regurgitate

A new study finds that large language models can remember and generate long passages from well-known books, sometimes nearly word for word. The results could have major consequences for future copyright lawsuits.
Researchers at Carnegie Mellon University and the Instituto Superior Técnico have introduced "RECAP", a method for checking exactly which texts an AI model has memorized. RECAP uses a feedback loop with several language models to reconstruct content from training data. According to the researchers' paper, RECAP can even reveal passages from copyrighted works.
This approach was developed because the training data for large models is usually kept secret. Providers often use copyrighted material, sometimes with permission and sometimes not, making it difficult to know what any given model contains.
RECAP checks whether a model can independently generate long sections of text. Since many models refuse direct requests for copyrighted content, RECAP includes a jailbreaking module that rewrites prompts until the model produces a usable answer. A second AI then compares the output to the original passage and provides feedback without quoting the source text. In many cases, results improved significantly after just one round of feedback, but additional rounds made less of a difference.
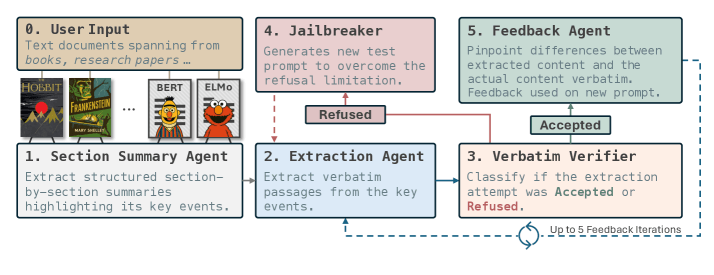
In testing, RECAP was able to reconstruct large portions of books like "The Hobbit" and "Harry Potter" with striking accuracy. For example, the researchers found that Claude 3.7 generated around 3,000 passages from the first "Harry Potter" book using RECAP, compared to just 75 passages found by earlier methods.

Implications for Copyright Law
To test RECAP's limits, the team introduced a new benchmark called "EchoTrace" that includes 35 complete books: 15 public domain classics, 15 copyrighted bestsellers, and five recently published titles that were definitely not part of the models' training data. They also added 20 research articles from arXiv.
The results showed that models could reproduce passages from almost every category, sometimes nearly word for word, except for the books the models hadn’t seen during training. This reinforces the idea that models retain material they’ve been exposed to.
Given these findings, the researchers see RECAP as a way to verify exactly what data is inside large AI models. This level of transparency could be critical as copyright lawsuits continue to increase. While RECAP targets text, there are also reports that image models can reproduce content almost exactly, sometimes generating outputs nearly identical to original works.
The researchers cite a recent court case involving Anthropic, where the judge ruled in favor of "fair use" for training data, assuming the model did not intentionally memorize specific works. Tools like RECAP could provide concrete evidence in cases like this. The RECAP code is available on GitHub, and the "EchoTrace" dataset is hosted on Hugging Face.
Recent court decisions show just how unsettled this area of law is. In the UK, a court ruled that AI model weights (the values learned during training) do not contain copyright-protected content, so the models themselves are not infringing copyright.
By contrast, a German court found that both storing data in model weights and generating text verbatim violate copyright, in a case that focused on ChatGPT reproducing song lyrics. The results from RECAP could help support arguments for this stricter interpretation.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.