Pix2pix-zero is designed to allow simple image editing using Stable Diffusion while keeping the structure of the source image.
For generative AI models such as Stable Diffusion, DALL-E 2, or Imagen, there are several methods such as Inpainting, Prompt-to-Prompt, or InstructPix2Pix that allow the manipulation of real or generated images.
Researchers at Carnegie Mellon University and Adobe Research now present pix2pix-zero, a method that focuses on preserving the structure of the source image. The method enables image translation tasks to be performed without extensive fine-tuning or prompt engineering.
Pix2pix-zero uses cross-attention guidance
Methods such as Prompt-to-Prompt or InstructPix2Pix can change the structure of the original image or stick to it so much that the desired changes are not made.
One solution is to combine Inpainting and InstructPix2Pix, which allows for more targeted changes. Pix2pix-zero takes a different approach: the researchers synthesize a completely new image, but use cross-attention maps to guide the generative process.
The method supports simple changes such as "cat to dog", "dog to dog with sunglasses" or "sketch to oil painting". The input is an original image, from which a BLIP model derives a text description, which is then converted into a text embedding by CLIP.
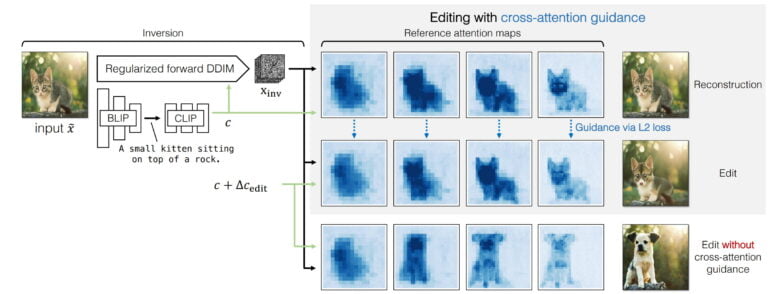
Together with an inverted noise map, the text embedding is used to reconstruct the original image. In the second step, the cross-attention maps from this reconstruction, together with the original text embedding and a new text embedding to guide the change, are used to guide the synthesis of the desired image.
Since the change "cat to dog" is not described in detail by text input, this new text embedding cannot be obtained from a prompt. Instead, pix2pix-zero uses GPT-3 to generate a series of prompts for "cat", e.g. "A cat washes itself, a cat is watching birds at a window, ..." and for "dog", e.g. "This is my dog, a dog is panting after a walk, ...".
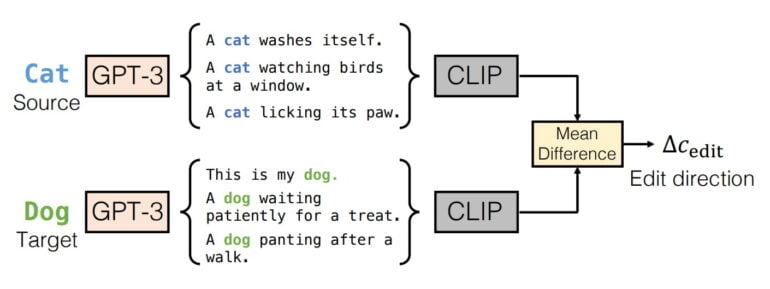
For these generated prompts, pix2pix-zero first calculates the individual CLIP embeddings and then the mean difference of all embeddings. The result is then used as a new text embedding for the synthesis of the new image, e.g. the image of a dog.

Pix2pix-zero stays close to the original
The researchers use several examples to show how close pix2pix-zero stays to the original image - although small changes are always visible. The method works with different images, including photos or drawings, and can change styles, objects, or seasons.
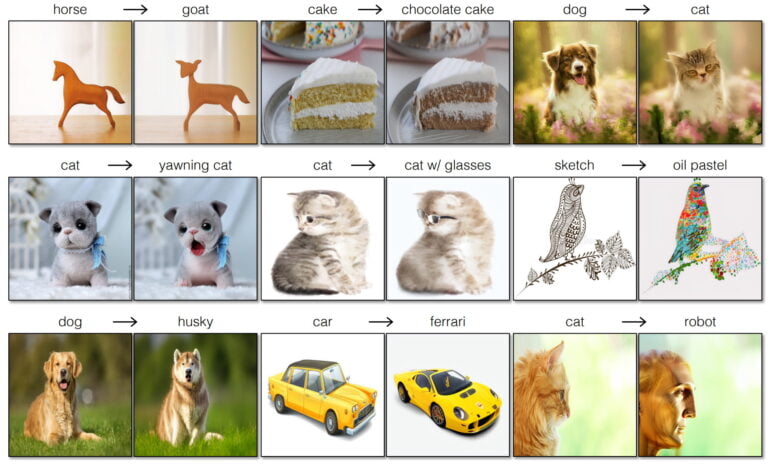
In a comparison with some other methods, pix2pix-zero is clearly ahead in terms of quality. A direct comparison with InstructPix2Pix is not shown in the paper.

The quality of the results also depends on Stable Diffusion itself, according to the paper. The cross-attention maps used for guidance show which features of the image the model focuses on in each denoising step, but are only available at a resolution of 64 by 64 pixels. Higher resolutions may provide even more detailed results in the future, according to the researchers.
Another drawback of the diffusion-based method is that it requires many steps and therefore a lot of compute power and time. As an alternative, the team proposes a GAN trained on the image pairs generated by pix2pix-zero for the same task.
Comparable image pairs have so far been very difficult and expensive to generate, the team says. A distilled version of the GAN achieves similar results to pix2pix-zero with a speedup of 3,800 times. On an Nvidia A100, this equates to 0.018 seconds per frame. The GAN variant thus allows changes to be made in real-time.
More information and examples can be found on the pix2pix-zero project page.