Starling-7B is a compact but capable LLM trained with AI feedback

UC Berkeley researchers present Starling-7B, an open Large Language Model (LLM) trained with Reinforcement Learning from AI Feedback (RLAIF).
Reinforcement Learning from AI Feedback (RLAIF) uses feedback from AI models to train other AI models and improve their capabilities. For Starling-7B, RLAIF improves the helpfulness and safety of chatbot responses. The model is based on a fine-tuned Openchat 3.5, which in turn is based on Mistral-7B.
If RLAIF sounds familiar, it's probably because you've heard of it in the context of ChatGPT, but with one crucial difference: For OpenAI's GPT-3.5 and GPT-4 models, humans improved performance by rating the model's output, a process called Reinforcement Learning from Human Feedback (RLHF). This was the "secret sauce" that made interacting with ChatGPT feel so natural.
Compared to human feedback, AI feedback has the potential to be cheaper, faster, more transparent, and more scalable - if it works. And Starling-7B shows that it might.
To train the model with RLAIF, the researchers created the new Nectar dataset, which consists of 183,000 chat prompts with seven responses each, for a total of 3.8 million pairwise comparisons. The responses come from various models, including GPT-4, GPT-3.5-instruct, GPT-3.5-turbo, Mistral-7B-instruct, and Llama2-7B.
The quality of the synthetic responses was scored by GPT-4. The researchers developed a unique approach to circumvent GPT-4's bias to score the first and second responses highest.

Starling-7B achieves strong benchmark results
The researchers used two benchmarks, MT-Bench and AlpacaEval, which use GPT-4 for scoring, to evaluate the performance of their model in terms of safety and helpfulness in simple instruction-following tasks.
Starling-7B outperforms most models in MT-Bench, except OpenAI's GPT-4 and GPT-4 Turbo, and achieves results on par with commercial chatbots such as Claude 2 or GPT-3.5 in AlpacaEval. In MT-Bench, the score increases from 7.81 to 8.09 compared to vanilla Openchat 3.5, and in AlpacaEval from 88.51% to 91.99%.

The researchers write that RLAIF primarily improves the model's helpfulness and safety, but not its basic capabilities such as answering knowledge-based questions, mathematics, or coding. These remained the same or were minimally degraded by RLAIF.
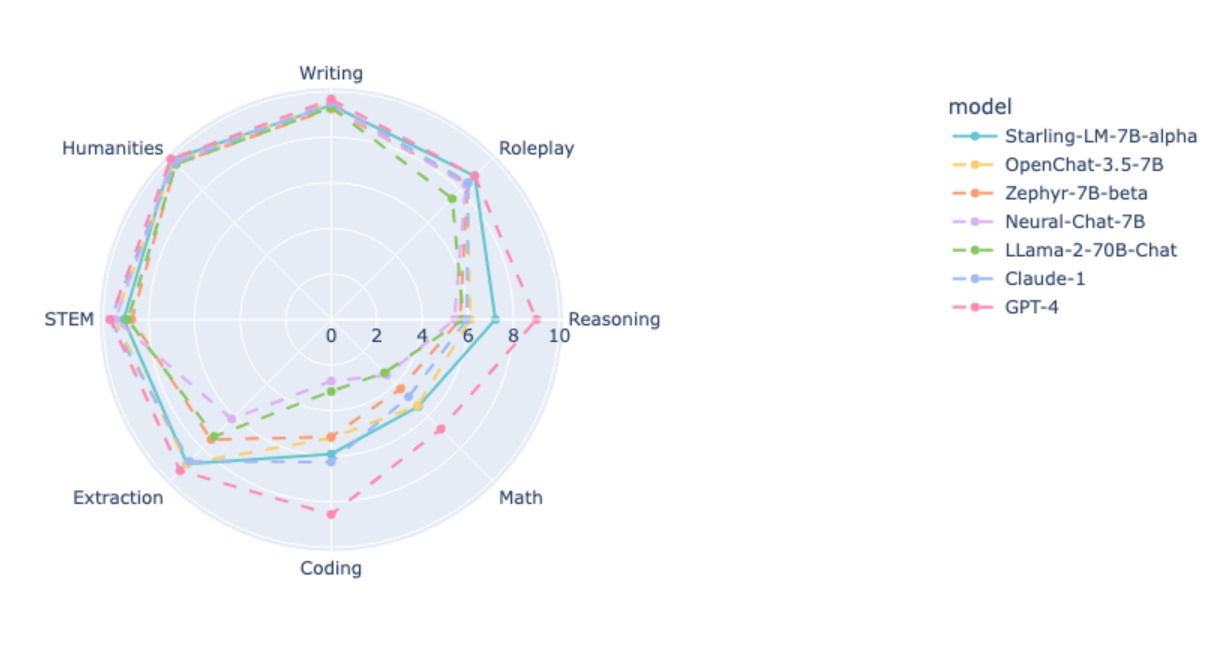
As usual, the benchmark results are of limited practical use. However, they are promising for the application of RLAIF, although the researchers point out that human raters may have different preferences than GPT-4, which rated in the benchmarks above. The next step could be to augment the Nectar dataset with high-quality human feedback data to better tailor the model to human needs.
RLHF primarily enhances the style of the responses, in particular aspects of helpfulness and safety, as evidenced in its performance in MT-Bench and AlpacaEval. However, these results do hint at the potential of scaling online RL methods using extensive preference data. Our result shows that when the gold reward model is GPT-4’s preferences, surpassing the performance of existing models is feasible with RLAIF. Therefore, adapting the preference data to include high-quality human responses could likely lead to improvements in aligning with human preferences.
Zhu et al.
Like other LLMs, large and small, Starling-7B has difficulty with tasks that require reasoning or mathematics, and the model hallucinates. It is also vulnerable to jailbreaks, as it has not been explicitly trained for these scenarios.
The researchers are publishing the Nectar dataset, the Starling-RM-7B-alpha reward model trained with it and the Starling-LM-7B-alpha language model on Hugging Face under a research license. Code and paper will follow shortly. You can test the model in the chatbot arena.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.