
The European companies show the first result of their cooperation: a language model of Aleph Alpha slimmed down by 80 percent.
Large language models like OpenAI's GPT-3 or Google's PaLM have well over a hundred billion parameters. Even with new insights into the role of training data in Deepmind's Chinchilla, larger models are to be expected.
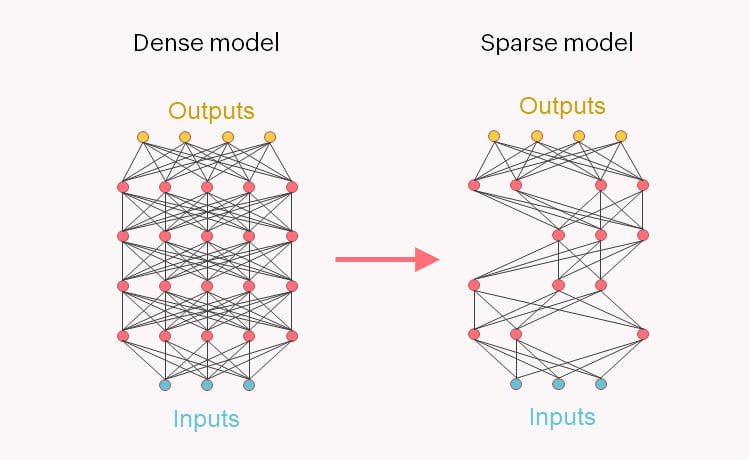
In fact, language models such as Google's Switch Transformer already exist with 1.6 trillion parameters, but they rely on sparse modeling, in Google's case specifically on a mixture-of-experts Transformer architecture.
Whereas with GPT-3, for example, all parts of the neural network are involved in every processing step, sparse models such as Switch Transformer use processes in which only parts of the network relevant to the task become active. This greatly reduces the computing power required for queries to the network.
A European AI collaboration shows first results
Google uses sparse modeling in the case of Switch Transformer to further scale language models. But conversely, it can also be used to train smaller networks with similar performance to larger models.
That's exactly what AI chipmaker Graphcore and AI startup Aleph Alpha have now done. The two European AI companies announced a collaboration in June 2022 that aims to develop large European AI models, among other things. The German Aleph Alpha recently launched Europe's fastest commercial AI data center.
Aleph Alpha CEO Jonas Andrulis pointed to the advantages of Graphcore's hardware for sparse modeling last summer, saying, "Graphcore’s IPU offers a new opportunity to evaluate advanced technological approaches such as conditional sparsity. These architectures will undoubtedly play a role in Aleph Alpha’s future research."
Graphcore and Aleph Alpha demonstrate lightweight Luminous language model
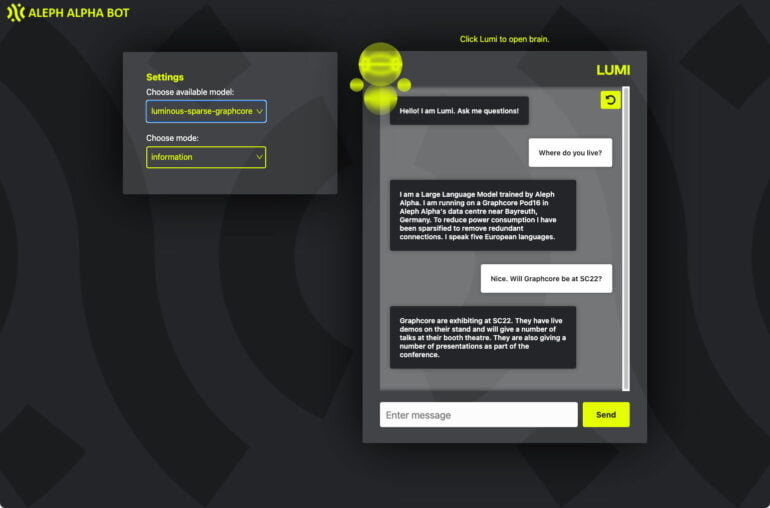
The two companies were able to slim Aleph Alpha's 13 billion parameters "Luminous Base" language model to 2.6 billion parameters. The companies also showed the slimmed-down variant running Lumi, a "conversational module" for Luminous.
The sparse modeling reduced nearly 80 percent of the model's weights while preserving most of its capabilities, according to the press release.

The new model uses point sparse matrix multiplications supported by Graphcore's Intelligence Processing Unit (IPU) and requires only 20 percent of the computational power and 44 percent of the memory of the original model, it said.
The small size allows the 2.6 billion-parameter model to be held entirely on the ultra-high-speed on-chip memory of a Graphcore IPU-POD16 Classic - achieving maximum performance. The model also requires 38 percent less power.
"Sparsification" central for next generation of AI models
For the next generation of models, "sparsification" will be critical, the companies said. It would enable specialized submodels to master selected knowledge more efficiently.
"This breakthrough in sparsification modeling impacts the commercial potential of AI companies like Aleph Alpha, enabling them to deliver high-performance AI models to customers with minimal computational requirements," the statement added.
Google is also following this path. In October 2021, AI chief Jeff Dean spoke for the first time about the search giant's AI future: Pathways is to one day become a kind of AI multipurpose system - and relies on sparse modeling as a central element.


