Genmo Mochi 1: A new benchmark for open AI video models

AI start-up Genmo has released its Mochi 1 video model as an open source version. According to the company, it is the largest publicly available AI model for video generation to date, with 10 billion parameters.
The model has been developed from scratch and, according to Genmo, sets new standards in two critical areas: the quality of movement and the accuracy with which text instructions are implemented.
Video: Genmo
Mochi 1 can generate videos at 30 frames per second and up to 5.4 seconds long. According to Genmo, it simulates physical effects such as liquids, fur, and hair movement with great realism.
Video: Genmo
According to the company, the model is optimized for photorealistic content and less suitable for animated content. Distortions can occasionally occur during extreme movements.
The current version of Mochi 1 produces videos at 480p resolution. An HD version with 720p resolution will follow later this year.
New architecture for efficient video generation
Technically, Mochi 1 is based on a new architecture called Asymmetric Diffusion Transformer (AsymmDiT). It processes text and video content separately, with the visual part using about four times as many parameters as the text processing part.
Unlike other modern diffusion models, Mochi 1 uses only a single language model (T5-XXL) to process prompts. This is intended to increase efficiency, but the developers have not yet published a scientific paper with more detailed information.
When implementing text prompts, the model achieves higher accuracy than the competition in benchmarks, while simulating complex physical effects more realistically in terms of motion quality.
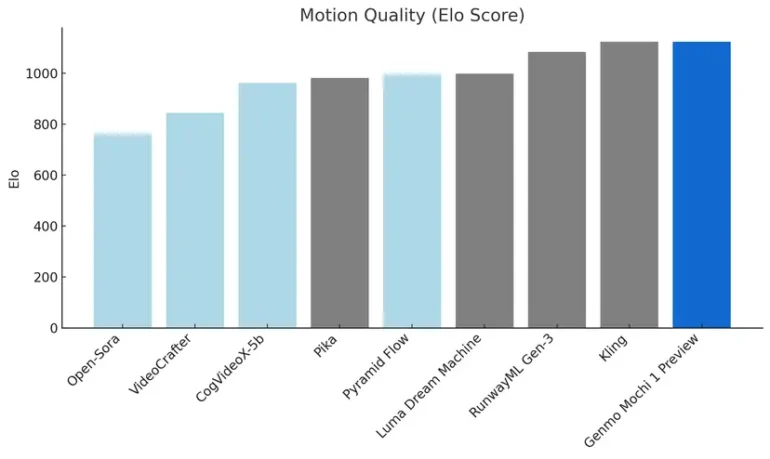
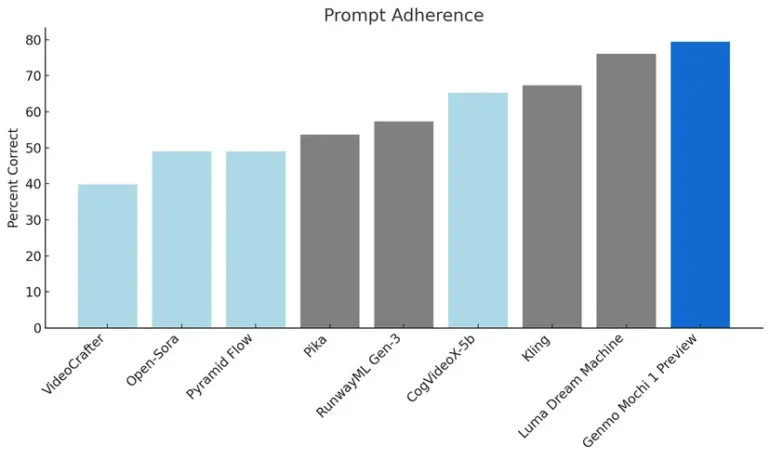
According to the self-description on the official website, Mochi 1 functions as a world model. Recent studies have cast doubt on this ability of video generators.
Genmo secures 28.4 million dollars in funding
Alongside the release of the model, Genmo announces a $28.4 million Series A funding round led by NEA. The Genmo team includes core members from major AI projects such as DDPM, DreamFusion and Emu Video.
The model weights and code are available under the Apache 2.0 licence on Hugging Face and GitHub. Interested parties can also try out the model for free via a rudimentary playground on the Genmo website, which also displays numerous examples from the community, including their prompt.
Although the quality is impressive for an open video model, commercial models such as Runway Gen-3 are currently ahead of the game. The tool based on it can produce both longer and higher-resolution clips and supports additional features such as image prompts, virtual camera movements or the transfer of facial expressions to an AI character. Other offerings are available from Kling, Vidu and MiniMax. Meta has also recently launched a new video model called Movie Gen.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.