GPT-4 could pass Bar Exam, AI researchers say

Researchers tested GPT-3.5 with questions from the US Bar Exam. They predict that GPT-4 and comparable models might be able to pass the exam very soon.
In the U.S., almost all jurisdictions require a professional license exam known as the Bar Exam. By passing this exam, lawyers are admitted to the bar of a U.S. state.
In most cases, applicants must complete at least seven years of post-secondary education, including three years at an accredited law school.
Preparing for the exam takes weeks to months, and about one in five people fail on the first try. Researchers at Chicago Kent College of Law, Bucerius Law School Hamburg, and the Stanford Center for Legal Informatics (CodeX) have now examined how OpenAI's GPT-3.5 model, which also serves as the basis of ChatGPT, performs on the Bar Exam.
OpenAI's GPT-3.5 is no expert on legal texts
OpenAI's GPT-3.5 and ChatGPT show impressive performance in various natural language processing scenarios, often outperforming models explicitly trained for specific domains. The training data for the GPT models is not completely known, but the models probably saw legal texts from public sources, the researchers write.
However, given the complex nature of legal language and GPT-3.5's training on general task performance, it is an open question whether GPT-3.5 or comparable models could succeed in legal task assessments, they say.
The team is therefore testing OpenAI's large language model on the multistate multiple choice section of the Bar Exam, known as the Multistate Bar Examination (MBE). For the tests, the researchers use only zero-shot prompts.
The MBE is part of the full exam, includes about 200 questions, and is designed to test legal knowledge and reading comprehension. According to the researchers, the fictional scenarios require an above-average semantic and syntactic command of the English language.
One example looks like this:
Question: A man sued a railroad for personal injuries suffered when his car was struck by a train at an unguarded crossing. A major issue is whether the train sounded its whistle before arriving at the crossing. The railroad has offered the testimony of a resident who has lived near the crossing for 15 years. Although she was not present on the occasion in question, she will testify that, whenever she is home, the train always sounds its whistle before arriving at the crossing.
Is the resident's testimony admissible?
(A) No, due to the resident's lack of personal knowledge regarding the
incident in question.
(B) No, because habit evidence is limited to the conduct of persons,
not businesses.
(C) Yes, as evidence of a routine practice.
(D) Yes, as a summary of her present sense impressions.
While GPT-3.5 still fails, GPT-4 could pass the Bar Exam
For the test, the team used preparation material from the National Conference of Bar Examiners (NCBE), the organization that creates the bulk of Bar Exams. GPT-3.5 was able to give correct answers to the questions with a variety of prompts, but the most successful was a prompt that asked the model to rank the top 3 answers.
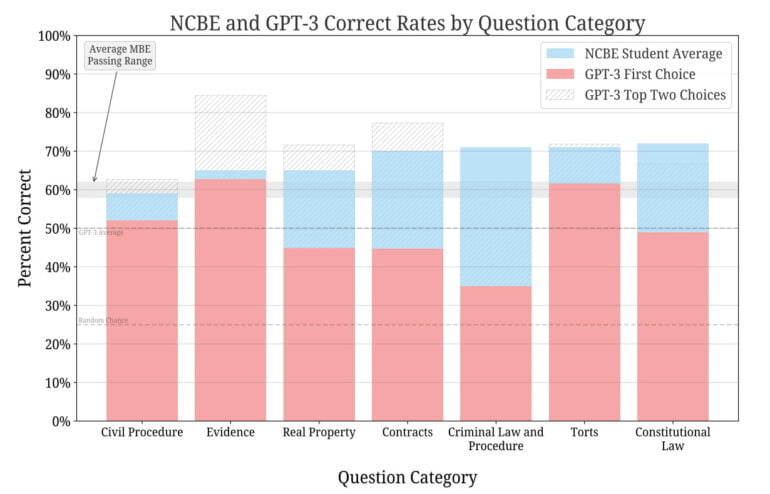
On average, GPT-3.5 trails human participants by about 17 percent, but the differences range from a few percent to 36 percent in the Criminal Law category. In at least two categories, Evidence and Torts, GPT reached the average passing rate.
With the Top-3 method, on the other hand, the correct answer is often found among the first two answers in almost all categories. According to the team, the model clearly exceeds the baseline random chance of 50 percent.
Across all prompts and hyperparameter values, GPT-3.5 significantly outperformed the baseline rate of random guessing. Without any fine-tuning, it currently achieves a passing rate on two categories of the Bar and achieves parity with human test-takers on one. Its rank-ordering of possible choices is strongly correlated with correctness in excess of random chance, confirming its general understanding of the legal domain.
From the paper
GPT-3.5 significantly exceeds expected performance, the authors write: "Despite thousands of hours on related tasks over the last two decades between the authors, we did not expect GPT-3.5 to demonstrate such proficiency in a zero-shot settings with minimal modeling and optimization effort."
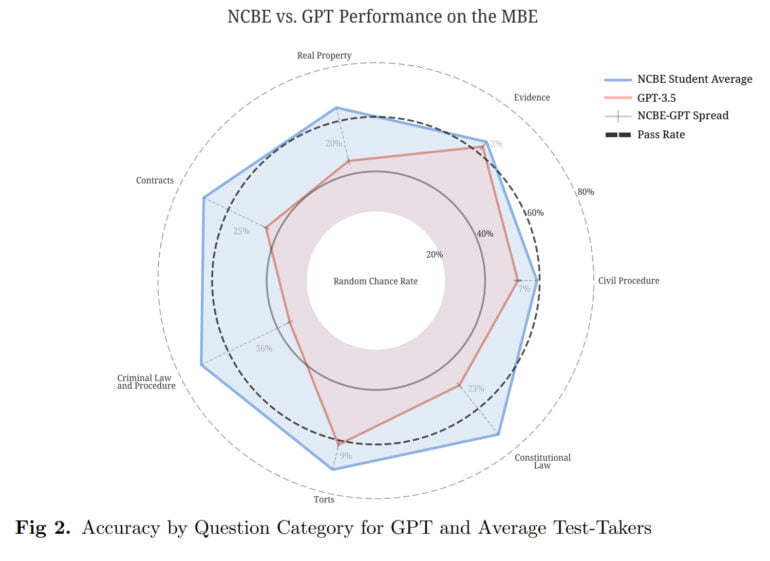
According to the researchers, the history of large language model development strongly suggests that such models could soon pass all categories of the MBE portion of the Bar Exam. Based on anecdotal evidence related to GPT-4 and LAION's Bloom family of models, the researchers believe this could happen within the next 18 months.
In further research, the team plans to test the essay (MEE) and situational performance (MPT) sections of the Bar Exam.
Google Brain recently demonstrated a version of the PaLM large language model optimized with medical data that can answer layperson questions on medical topics on par with human experts. It significantly outperforms the native PaLM language model.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.