
Meta introduced Chameleon, a new multimodal model that seamlessly processes text and images in a unified token space. It could be a precursor to a GPT-4o alternative.
Meta AI introduced Chameleon, a new approach to training multimodal foundation models that process both text and images as discrete tokens. Unlike previous methods, Chameleon uses a unified transformer architecture and forgoes separate encoders or decoders for different modalities, as employed by other architectures like Unified-IO 2.
Meta's model is trained from the ground up with a mix of text, images, and code. The images are first quantized into discrete tokens that can be processed analogously to words in text.
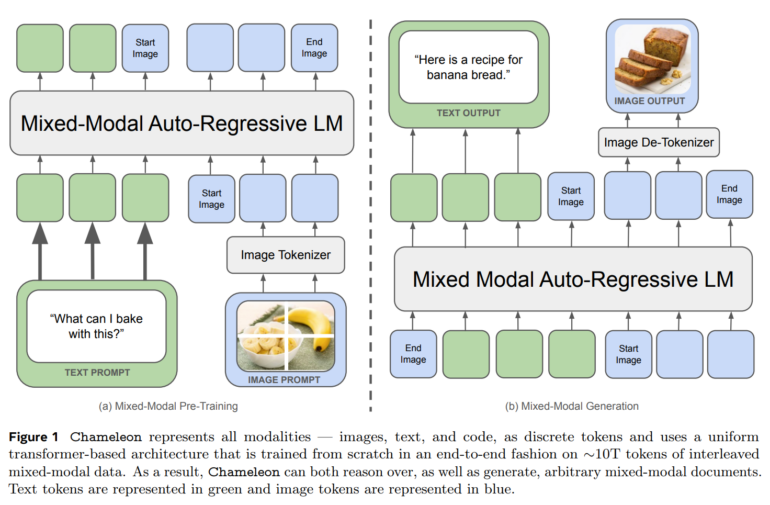
This "early-fusion" approach, where all modalities are projected into a common representation space from the beginning, allows Chameleon to seamlessly reason and generate across modalities. However, this poses significant technical challenges for the researchers, particularly in terms of training stability and scalability.
To overcome these challenges, the team introduces a series of architectural innovations and training techniques. They also demonstrate how the supervised finetuning methods used for pure language models can be transferred to the mixed-modal case.
Chameleon consistently shows strong performance across all modalities
Using these techniques, the team successfully trained the 34 billion parameter Chameleon model with 10 trillion multimodal tokens - five times more than the pure text model Llama-2. In comparison, the language model Llama-3 was trained with 15 trillion text tokens, so future versions of Chameleon will likely be trained with significantly more tokens.
Extensive evaluations show that Chameleon is a versatile model for a wide range of tasks. The 34 billion model achieves top performance in visual question answering and image captioning, surpassing models like Flamingo, IDEFICS, and Llava-1.5, and approaching GPT-4V. At the same time, it remains competitive in pure text tasks, achieving similar performance to Mixtral 8x7B and Gemini-Pro in common sense and reading comprehension tests.
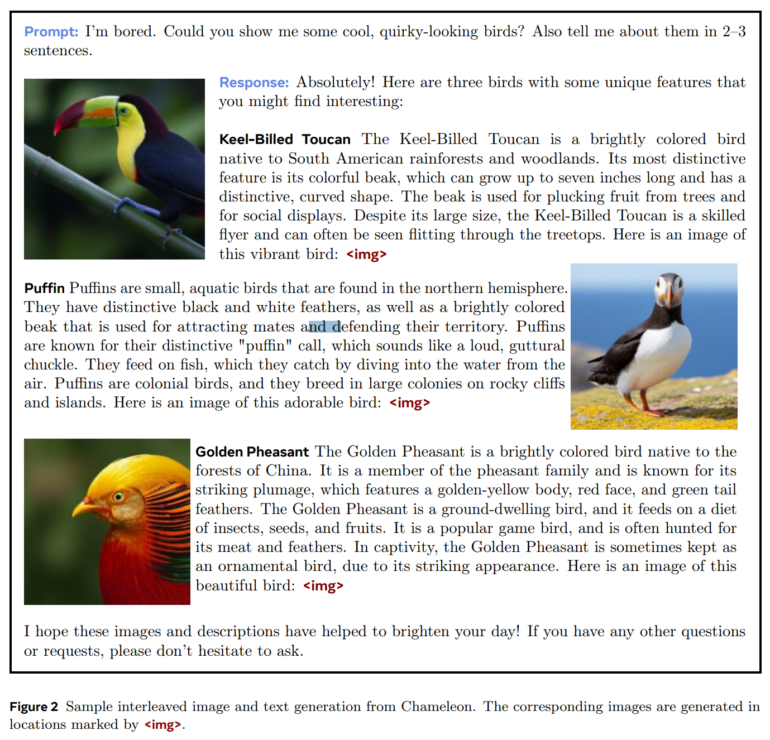
However, the most interesting aspect is the entirely new capabilities Chameleon offers in mixed-modal inference and generation. In one test, Meta shows that human evaluators prefer the 34 billion model to Gemini-Pro and GPT-4V in terms of the quality of mixed-modal responses to open-ended questions, i.e., questions that mix images and text. It can also answer questions that include text and generated images.

Meta could soon show an answer to GPT-4 Omni
Although little is known about the specific architecture of the recently introduced GPT-4 omni (GPT-4o) from OpenAI, the company is likely pursuing a similar approach. However, in contrast to Chameleon, OpenAI's model also directly incorporates audio, is presumably significantly larger, and generally trained with much more data.

According to Armen Aghajanyan, an involved AI researcher at Meta, Chameleon is only the beginning of Meta's work to share knowledge about the next paradigm of scale: "Early-fusion" multimodal models are the future. The researcher also noted that the model was trained five months ago and the team has made great progress since then. Integrating additional modalities could be one of them. Meta CEO Mark Zuckerberg has already announced multimodal models for the future.
Chameleon is not yet available.


