Alibaba's Qwen2 sets new standards for open source language models
Alibaba's cloud computing unit's latest model takes the lead in benchmarks compared to other open-source models.
Alibaba's cloud computing unit has been working on a powerful language model called Qwen for some time. Now, the latest version, Qwen2, has been released with significant improvements in areas like programming, math, logic, and multilingual understanding. The researchers only released the first generation in August 2023.
Trained with many more languages
According to the Qwen team's blog post, Qwen2 includes pre-trained and instruction-tuned models in five sizes, ranging from 0.5 billion to 72 billion parameters. The models were trained with data in 27 more languages, including German, French, Spanish, Italian, and Russian, in addition to English and Chinese, which the team believes will strengthen their multilingual capabilities.
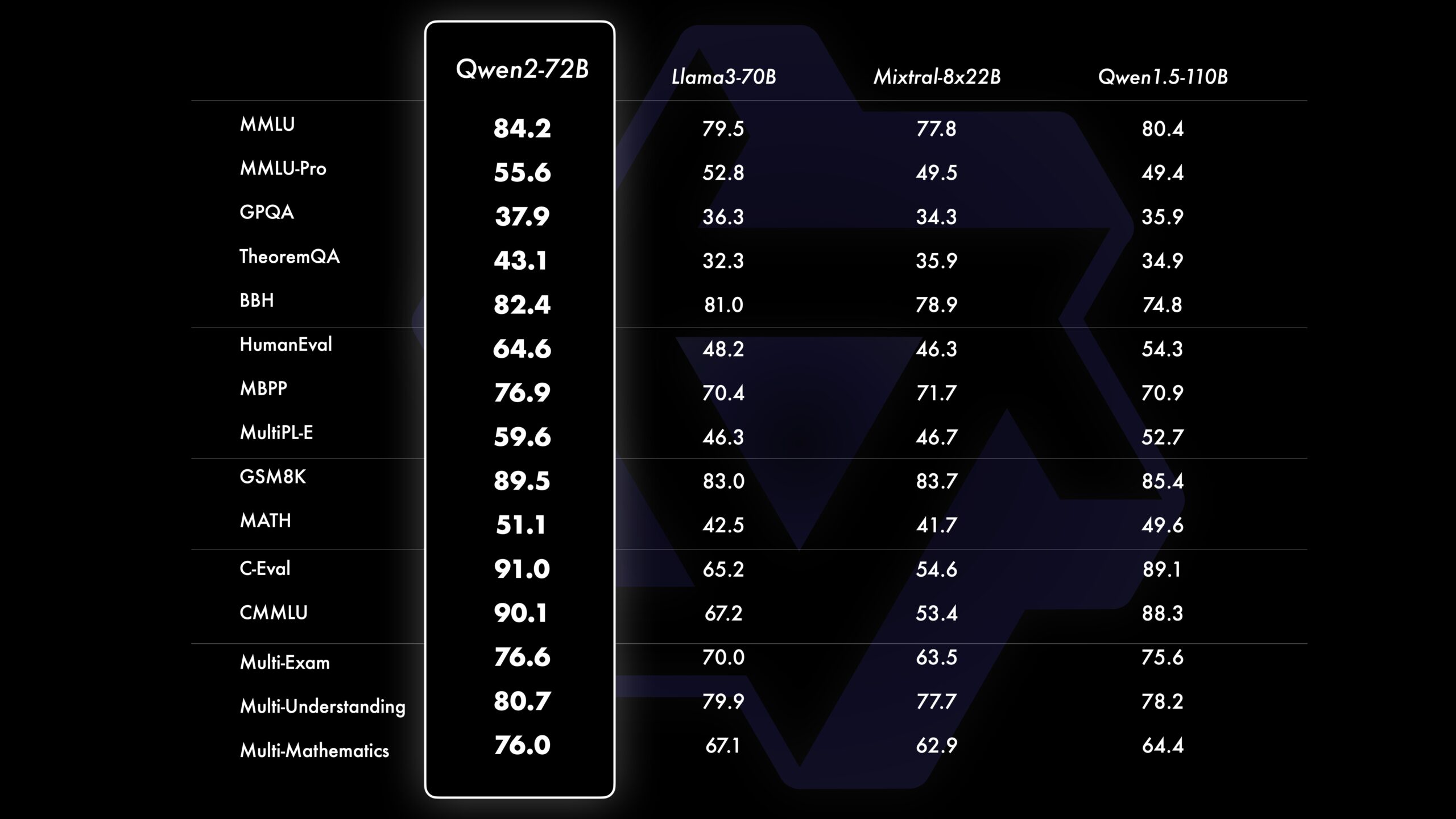
Compared to its predecessor, Qwen2 also offers improved performance in programming and math. In particular, Qwen2-72B-Instruct shows significant improvements in various programming languages by integrating experiences and data from CodeQwen1.5. In a comparison shown by the team, Qwen2-72B outperforms Meta's Llama3-70B in all tested benchmarks, sometimes by a wide margin.
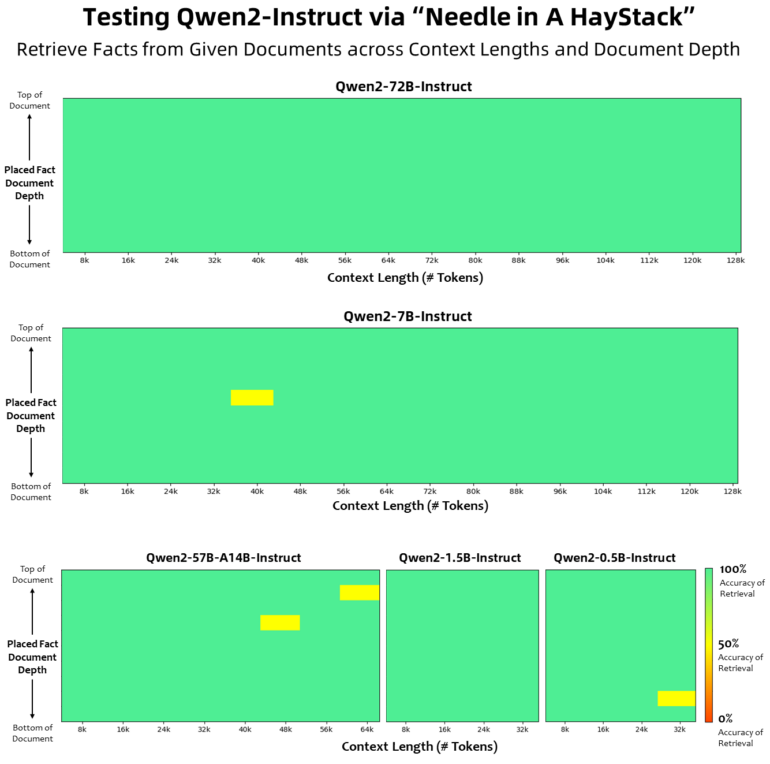
Qwen2 reliably finds a needle in a haystack
The Qwen2 models also show an impressive understanding of long contexts. All instruction-tuned models were trained with context lengths of at least 32,000 tokens. Qwen2-72B-Instruct can handle information extraction tasks within a context of 128,000 tokens without errors, while Qwen2-57B-A14B supports 64,000 tokens. Language models traditionally struggle with this "Needle in a Haystack" problem, especially with large context windows.
Regarding safety and responsibility, the Qwen team conducted tests with unsafe queries translated into multiple languages. They found that the Qwen2-72B-Instruct model performs comparably to GPT-4 in terms of safety and significantly outperforms Mistral-8x22B.
However, like other Chinese language models, Qwen2 refuses to answer questions about the Tiananmen Square massacre and other taboo topics in Chinese discourse.
New open-source license for most models
With this release, the Qwen team has also changed the licenses for its models. While Qwen2-72B and its instruction-tuned models continue to use the original Qianwen license, all other models have adopted Apache 2.0. The team believes that the improved openness of their models to the community can accelerate Qwen2's applications and commercial use worldwide.
In the future, the Qwen team plans to train even larger Qwen2 models, including multimodal variants with image and audio data. The researchers also want to release future models as open-source.
The researchers have uploaded the code and weights to GitHub and Hugging Face, respectively. A demo for Qwen2-72B-Instruct can be found here. A technical paper with more details on the structure and training data is still missing but is expected to follow soon.
The Qwen team is relying on partners to facilitate tasks like fine-tuning, local execution, or integration with RAG systems.
![]()
Open-source models continue to be successful, not in terms of their spread, but at least in terms of their technical capabilities. In recent months, not only Meta's LLaMA 3 has been released, but also Mixtral-8x22B and DeepSeek-V2, all of which are neck-and-neck in benchmark lists.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.