
DeepFloyd IF is a text-to-image model that handles text particularly well and is basically an open-source version of Google's Imagen.
In May 2022, Google demonstrated Imagen, a text-to-image model that outperformed OpenAI's DALL-E 2, which had just been released at the time. According to the team and the examples shown, the model beat DALL-E in accuracy and quality of text-to-image synthesis. It was also able to generate text in images, a capability that no open-source model has been able to do reliably.
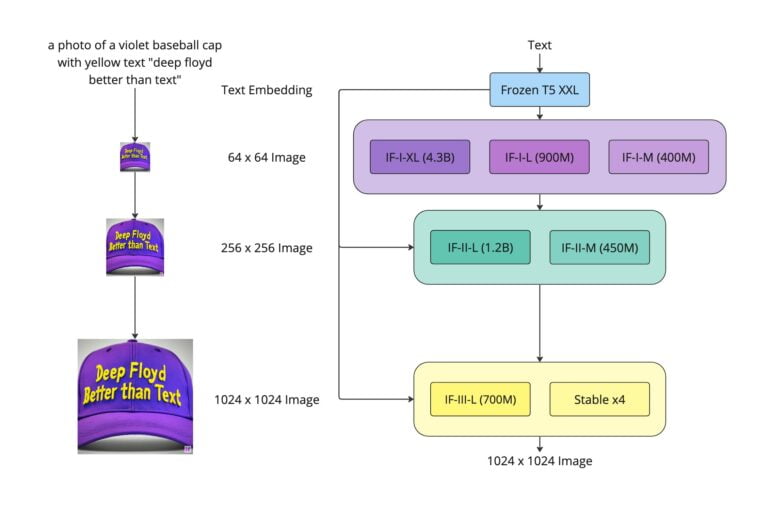
As with other generative AI models such as Stable Diffusion or DALL-E 2, the Google team relied on a frozen text encoder that converts text prompts into embeddings, which are then decoded into an image by a diffusion model. Unlike other models, however, Imagen does not use the multimodally trained CLIP, but rather the large T5-XXL language model. The team was even able to show that the quality of the generated images increases more with the size of the language model than with the training of the diffusion model, which is actually responsible for image synthesis.
DeepFloyd IF is an open-source Imagen
Now the DeepFloyd team, affiliated with StabilityAI, has replicated this architecture and released a kind of open-source image called IF. According to the team, IF demonstrates the high image quality and language understanding capabilities of Imagen. It was trained with around 1.2 Billion images from the LAION-5B dataset.
In tests, it even outperforms Google Imagen, achieving a Zero-Shot FID score of 6.66 on the COCO dataset, also ahead of other available models such as Stable Diffusion.




According to the team, IF also supports Image-to-Image-Translation and Impainting.
Video: DeepFloyd
Like Imagen, DeepFloyd IF relies on two super-resolution models that bring the resolution of the images to 1,024 x 1,024 pixels, and offers different model sizes with up to 4.3 billion parameters. For the largest model with an upscaler to 1,024 pixels, the team recommends 24 gigabytes of VRAM, while the largest model with a 256-pixel upscaler still requires 16 gigabytes of VRAM.
DeepFloyd shows next level of text-to-image synthesis
According to DeepFloyd, the work shows the potential of larger UNet architectures in the first stage of cascaded diffusion models, and thus a promising future for text-to-image synthesis. In other words, DeepFloyd's IF clearly shows that generative AI can get even better and that the open-source community could achieve models like Google's Parti in the future, which surpasses Imagen in some aspects.

The first version of the IF model is subject to a restricted license, intended for research purposes only - i.e. non-commercial purposes - to temporarily gather feedback. After this feedback has been collected, the team of DeepFloyd and StabilityAI will be releasing a completely free commercially compatible version.
DeepFloyd's IF has a Github, a demo is available on HuggingFace. More information is available on the DeepFloyd website.



