
Researchers demonstrate that predicting multiple tokens during the training of AI language models improves performance, coherence, and reasoning capabilities. Does the future of large language models lie beyond simple token prediction?
Large language models like GPT-4 are typically trained using "next token prediction." The AI system learns to predict only the next word in a sentence. Scientists from Meta AI, CERMICS (Ecole des Ponts ParisTech), and LISN (Université Paris-Saclay) now propose that the models should predict several words at once instead. They call this method "multi-token prediction."
Specifically, the model predicts the next words in parallel at each point in the training text by using a shared model component (trunk) and numerous independent output heads.
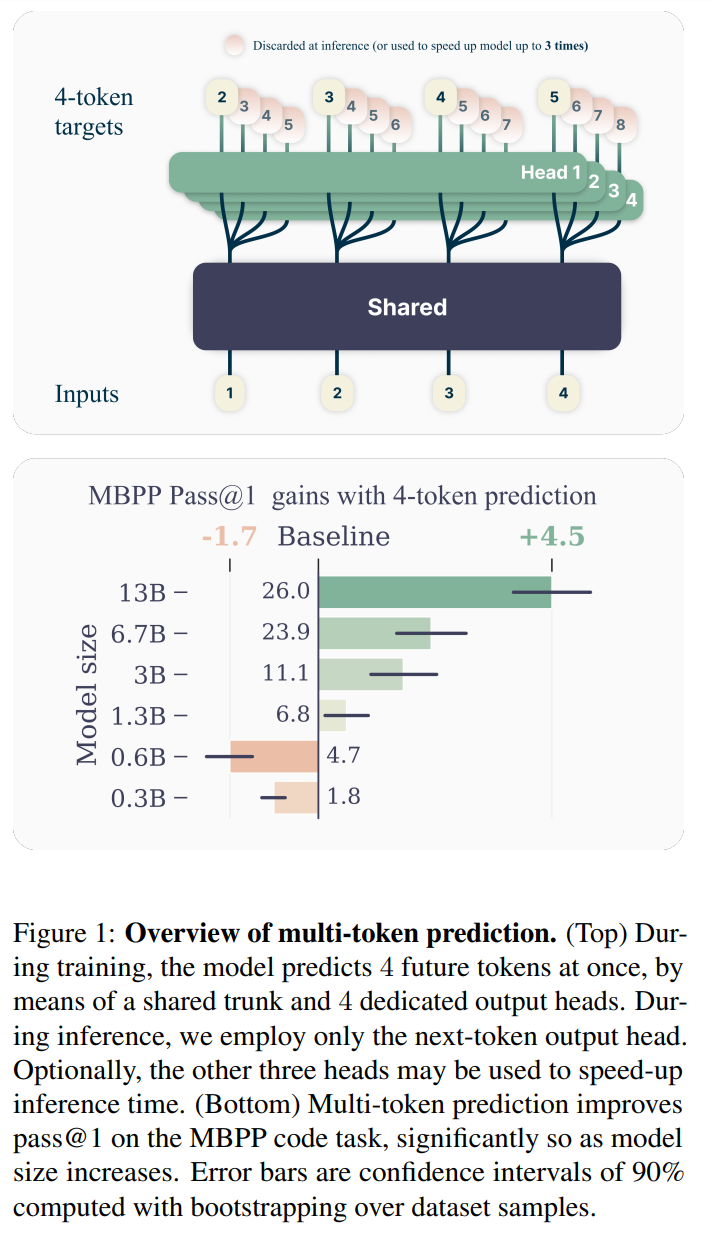
To keep memory requirements low, the calculations of the output heads are performed sequentially, and the intermediate results are deleted after each step. This way, the memory requirements do not increase with the number of predicted words.
The experiments show that the advantage of multi-token prediction increases with the size of the model. A model with 13 billion parameters solved 12 % more programming tasks on the HumanEval dataset and 17 % more on the MBPP dataset than a comparable next-token model.
The new approach also scores in terms of execution speed: With speculative decoding, which utilizes the additional prediction heads, the models can be executed up to three times faster.
Why does multi-token prediction work so well? The researchers suspect that next-token models focus too much on immediate prediction, while multi-token models also consider longer-term dependencies. They, therefore, hope that their work will generate interest in novel auxiliary tasks when training language models beyond mere next-token prediction to improve their performance, coherence, and reasoning capabilities. Next, they want to develop methods that operate in the embedding space - an idea that Meta's AI chief Yann LeCun sees as central to the future of AI.
The human brain does more than just predict the next token
The initiative is part of a series of recent developments aimed at bringing AI language models closer to how the human brain functions. LeCun, for example, is researching the "Joint Embedding Predictive Architecture" (JEPA) for autonomous artificial intelligence. Its central "world model" module is expected to learn a hierarchical and abstract representation of the world, which can be used to make predictions at various levels of abstraction - comparable to the human brain.
Studies suggest that the brain thinks further ahead when understanding language than current AI models. Instead of just predicting the next word, it predicts several subsequent words at once. In addition, it uses semantic information alongside syntactic information for more extensive and abstract predictions.

These findings result in a research task for AI: the prediction of hierarchical representations of future inputs is needed for better language algorithms, according to neuroscientist Jean-Rémi King from the French research center CNRS, who leads the Brain & AI team at Meta.
His team showed in late 2021 that human brain responses to language are predictable based on activations of a GPT language model. In June 2022, the team showed correlations between an AI model trained with speech recordings and fMRI recordings of more than 400 people listening to audiobooks. King's team then demonstrated an AI system that can predict which words a person has heard from MEG and EEG data. Later, a paper by researchers at the University of Texas at Austin replicated a similar result for fMRI recordings.
An accurate prediction of long word sequences is difficult due to the combinatorial possibilities. However, more abstract representations, such as the meaning of word sequences, allow for more reliable predictions.
By this logic, with multi-token prediction and future approaches that go beyond simple word prediction, the vision of AI models that overcome many of the weaknesses of today's models may be getting closer. Just how close remains to be seen.


